
Una cosa sorprendente sugli LLM di cui nessuno parla
Una piccola riflessione sull'inaspettata potenza delle reti sintattiche.


Come probabilmente sapete, gli LLM (Large Language Models) sono diventati una questione morale.[1] Da quando sono stati popolarizzati un anno e mezzo fa, sono stato bombardato da un flusso interminabile di terribili opinioni. Dai tech-bro che affermano che, nei prossimi 2-3 anni, gli LLM scriveranno il prossimo bestseller, faranno film su misura o risolveranno tutti i problemi del mondo (spoiler: non accadrà), alle aziende che usano "AI" dove non ha alcun senso, fino alla folla di persone che si sentono intelligenti postando screenshot di indovinelli che i chatbot non riescono a risolvere (come se a qualcuno importasse) o che lanciano attacchi contro le "AI" dimostrando contemporaneamente quanto poco sappiano sull'argomento.
Oggi voglio dimenticarmi di tutto questo per un momento. Solo un momento.
Respiriamo. Ah! Non è piacevole?
Vorrei che dimenticaste tutte le opinioni preesistenti sugli LLM. Disconnettetevi dal mondo materiale e seguitemi nel dominio puramente matematico. Voglio solo rendervi partecipi di una delle loro meravigliose proprietà, qualcosa di così affascinante che mi dà la stessa sensazione di meraviglia che provo guardando la spirale di una galassia o gli anelli di Saturno.
Cosa è un LLM?
Prima di tutto, chiariamo una cosa. I Large Language Models (LLM) sono modelli del linguaggio umano. Possono essere usati per la generazione di testo, ma intrinsecamente non è la loro unica funzione.
Voglio sottolineare questo punto perché l'equivalenza tra LLM e "generazione di testo" è ripetuta così spesso che anche ChatGPT sbaglia.
Quindi, gli LLM sono modelli, e qualsiasi modello può essere usato per generare cose. Si inserisce qualcosa in ingresso, si esegue il modello e si ottiene qualcosa in uscita. Poi si ripete. E si ripete. E si ripete. Ad libitum.
Ok. Se la generazione è il processo di applicare gli LLM (e altre cose) a un input, che cos'è, materialmente parlando, un LLM?
Precisazione: semplificherò le cose al punto da essere tecnicamente incorretto. Lo so. Tuttavia, voglio dare alle persone un'idea approssimativa dei concetti matematici dietro gli LLM. Se conoscete l'argomento, passate semplicemente alla sezione successiva.
Grossolanamente parlando, un LLM è un mucchio di numeri. Tuttavia, è più utile pensarle come un contenitore di word embeddings.
Potete immaginare un word embedding come una lista lunghissima di numeri che rappresentano un punto in uno spazio multidimensionale. Mentre il nostro spazio fisico ha tre dimensioni (su-giù, sinistra-destra, avanti-indietro), lo "spazio delle parole" ha centinaia o addirittura migliaia di dimensioni. Pertanto, ogni parola può essere rappresentata da 200, 500, se non addirittura migliaia di numeri.
Perché è utile? Perché possiamo fare matematica con i numeri e, di conseguenza, fare matematica con le parole. Per esempio, posso trovare i punti più vicini a X per ottenere parole correlate a X usando il teorema di Pitagora. Oppure posso sottrarre e aggiungere parole insieme per ottenere nuove parole. Un esempio comune: si possono fare cose come "re" - "uomo" + "donna" = "regina".
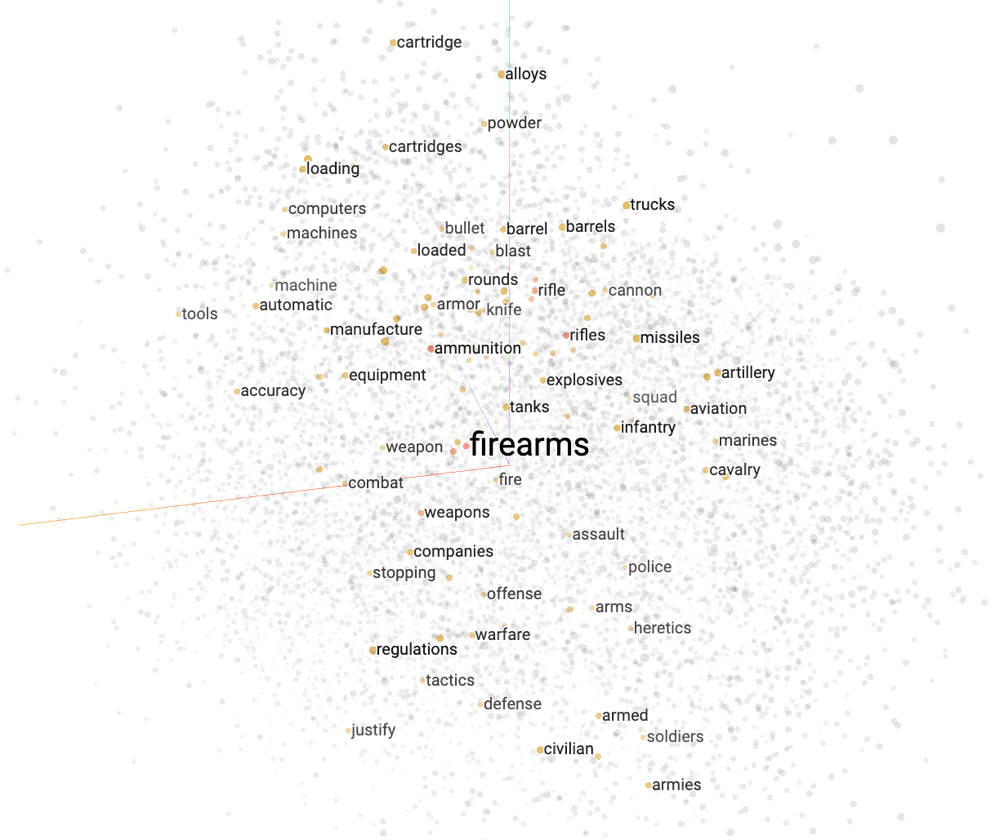
La cosa bella è che gli algoritmi apprendono questi numeri esaminando solamente quali parole sono usate nello stesso contesto.
NOTA: Una confessione per chi vuole un discorso più tecnico: dire che "gli LLM contengono embedding" è sbagliato. I modelli LLM sono più complessi di così; dopotutto sono reti neurali. È tecnicamente possibile ottenere le word embedding dagli LLM, ma non è banale. Il compito è particolarmente difficile per i modelli autoregressivi come GPT perché l'informazione del "word embedding" è distribuita su più livelli nascosti. Tuttavia, spero di avervi dato un'idea di come algoritmi e macchine possano giocare con le parole da un punto di vista puramente matematico.
La cosa sorprendente
Dopo questa lunga introduzione, è finalmente il momento di parlare della cosa sorprendente.
Come abbiamo visto, non c'è alcun momento nell’apprendimento di un LLM in cui prendiamo in considerazione la semantica del linguaggio (cioè, “cosa significano le parole”). Gli LLM considerano solo le posizioni relative delle parole (ad esempio, dove sono posizionate le parole l'una rispetto all'altra, quanto spesso appaiono in un testo, quali parole appaiono frequentemente vicino ad altre parole, e così via). Cioè, gli LLM apprendono solo la sintassi delle lingue.
Eppure, la generazione di testo da parte degli LLM ci ha mostrato che la rete sintattica di una lingua assorbe dentro di se parte della semantica. Gli LLM possono prendere un ingresso testuale, comprendere solo le sue proprietà sintattiche e generare un testo che abbia senso semanticamente.
Sì, lo so. La generazione di testo basata su LLM può fallire, allucinare, scrivere disinformazione e totali assurdità. Ma il fatto che possa produrre qualcosa di rilevante alla domanda, che abbia senso compiuto, e con l’inaspettato buon livello di accuratezza, è la cosa più vicina a un miracolo linguistico-computazionale che io conosca.
Ovviamente, è solo "parte della semantica." Ci sono numerose classi di elementi semantici che gli LLM mancano completamente. Per esempio, il ragionamento temporale non può essere dedotto dalla sola sintassi perché, per definizione, richiede una rappresentazione di livello superiore.[2]
Tuttavia, quel pezzo di semantica che sono in grado di apprendere è comunque molto utile per due motivi. Primo, ci fornisce una base computazionale per sperimentare con il significato di significato. In altre parole, abbiamo qualcosa di concreto che rappresenta il significato semantico.[3] Secondo, ci aiuta a identificare quali classi di "concetti semantici" NON sono deducibili dalla sintassi del linguaggio, il che è comunque istruttivo.
Gli LLM da qui in avanti
Gli LLM sono qui per restare, e il loro aspetto generativo è probabilmente la parte meno interessante (almeno per me). Ciò che fanno è fornire nuovi strumenti per interagire con quell’incubo di complessità che è il linguaggio umano.
Per questo motivo, vedo due direzioni:
- Modelli più potenti che possono fare “più cose un po' meglio” ma con rendimenti marginali decrescenti, almeno fino alla prossima svolta che aprirà nuovi orizzonti sul paesaggio semantico. Orizzonti che non possono raggiunti con i soli LLM (ma che lo saranno, per esempio, combinando gli LLM con qualcosa di nuovo o con rimpiazzandoli del tutto con algoritmi inediti).
- Modelli più piccoli, on-device (auspicabilmente eseguiti su chip neuromorfici specializzati). Non saranno usati per la generazione di testo (o per lo meno non sarà quella la loro funzione principale), ma saranno usati come middleware per i sistemi di AI basati su regole classiche. Perché? Perché il linguaggio umano è un disastro, e gli LLM sono il migliore strumento che abbiamo per lavorare con quel disastro in modo robusto.
Comunque vada, sono ben consapevole che il panorama dalla AI, al momento, è sovrastimato e pieno di idioti. Quindi non so quante persone apprezzeranno che io parli delle proprietà accessorie dei sistemi di AI. E ancora meno saranno quelli che condivideranno il mio entusiasmo.
Ma per quello che vale, mi sono divertito a scrivere di qualcosa che mi ha sorpreso positivamente. Una piccola proprietà matematico-linguistica che può gettare un po’ di luce su come il modello organico che teniamo nel nostro cranio possa essersi evoluto dal caos disordinato del mondo.
Questo articolo è la traduzione di un articolo che ho scritto in inglese sul mio blog.
Note
[1]: Oserei dire “prevedibilmente,” in quanto viviamo nella più stupida delle ere della civiltà umana: quella dove tutto è “una questione morale.”
[2]: Le query temporali complesse (come, ad esempio, come minimizzare il tempo di spedizione di un insieme di articoli in un problema di logistica) richiedono pianificazione, e gli LLM non possono pianificare, come dimostrato da Sébastien Bubeck et al. nel loro articolo "Sparks of artificial general intelligence: Early experiments with gpt-4." arXiv preprint arXiv:2303.12712 (2023)
[3]: Possiamo già vedere alcuni esperimenti divertenti su questo fronte. Ad esempio, Golden Gate Calude ci insegna come manipolare le reti neurali per indirizzare l'output del modello, ma è anche un modello per i ”pensieri intrusivi" e per “l’avvelenamento semantico". Roba affascinante.



